ディープエージェント型AIは、企業のリサーチ業務を「人による情報探索」から「目標主導の自律的調査」へと根本的に転換します。本稿は、その仕組み、活用領域、そして導入を成功に導くための運用原則を解説します。
貴社のリサーチプロセスには、見えないコストが存在する
多くの企業経営者は、リサーチ業務をコストセンターとして捉えていません。しかし、本来であれば捉えるべきです。競合分析、市場規模調査、デューデリジェンスレポートを必要とするたびに発生するコストは、成果物そのものに対する対価だけではありません。これまで自動化が困難であった業務に、高給で雇用された人材が費やす膨大な時間こそが、真のコストです。
数字自体は周知のものですが、改めて直視する価値があります。ナレッジワーカーは、週の労働時間の約3分の1を情報の「分析」ではなく「探索」に費やしています。複雑なリサーチタスク1件あたり、平均して7つ以上の分断されたシステムにアクセスする必要があります。そして、このオーバーヘッドを吸収しているのは、最も経験豊富で、最もコストの高い従業員たちです。
皮肉なことに、問題はデータ不足ではありません。多くの企業はむしろデータの洪水に溺れています。レポート、リサーチ、インサイトが、SharePoint、社内Wiki、有償データベース、メールスレッドの中に埋もれているのです。失敗しているのは「生成」ではなく、意思決定が求めるスピードでの「検索・統合・提供」のプロセスです。
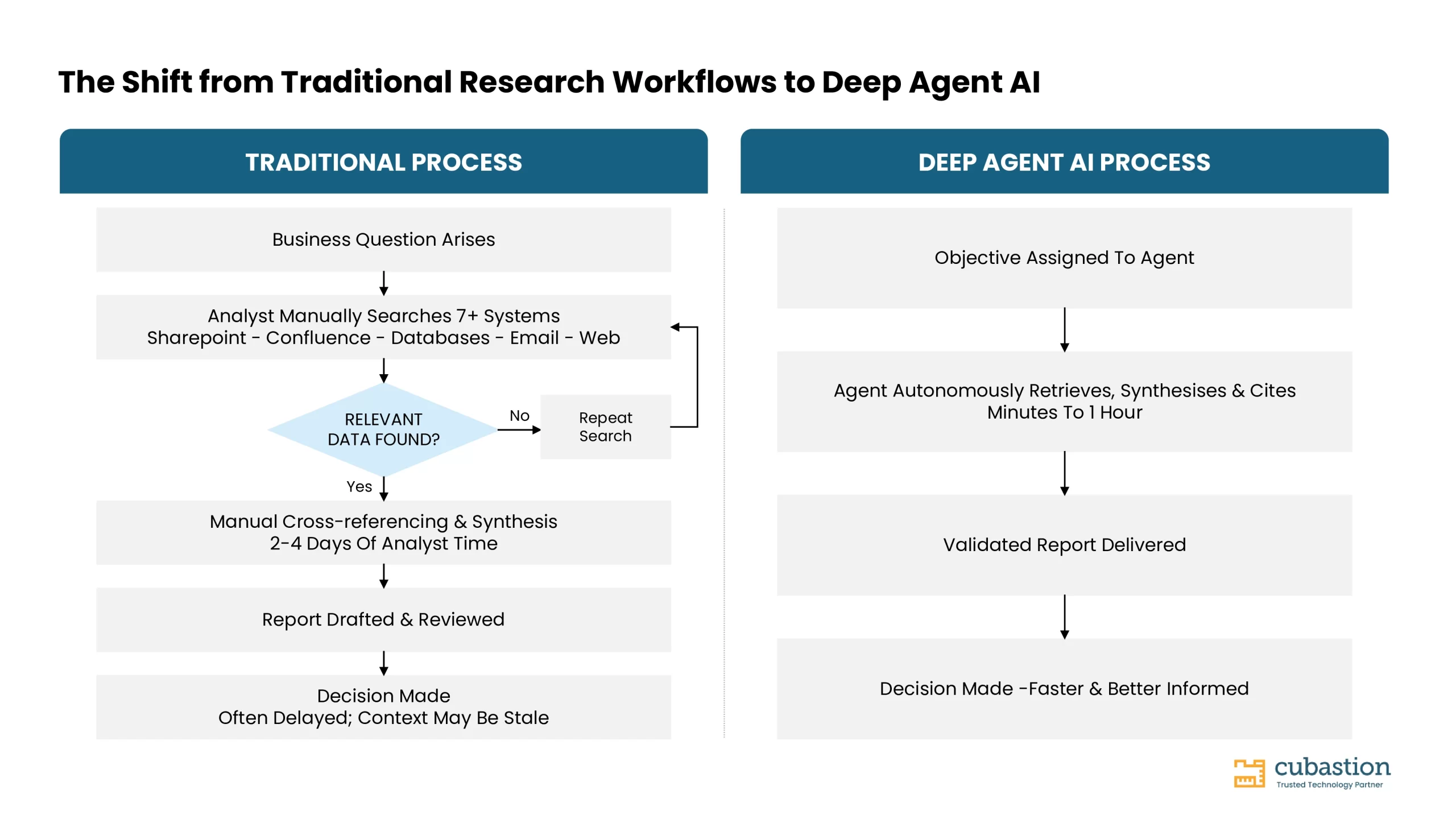
AIの三世代と、本世代が決定的に異なる理由
ディープエージェント型AIを「従来のAIの高速版」と捉えたくなる気持ちは理解できますが、それは誤りです。なぜ異なるのかを理解することが極めて重要です。なぜなら、それによって、何を導入しているのか、そして何を期待すべきかが根本的に変わるからです。
第一世代「クエリ・レスポンス型」。初期のGoogle検索やIBM Watsonのようなツールは、キーワードをインデックス化されたコンテンツと照合することで直接的な質問に回答しました。高速ではありますが、適用範囲は限定的であり、判断の責任は完全に人間側に残されていました。
第二世代「タスク支援型」。ChatGPTやGitHub Copilotといったツールは、指示を受ければドラフト作成、要約、アウトプット生成が可能になりました。真の前進ではありましたが、依然として受動的であり、各ステップで指示を待つ必要がありました。
第三世代「ディープエージェント型」。OpenAI Deep Research、Perplexity Pro、ツール利用機能を備えたAnthropic Claudeといったツールは、高次の目標を受け取り、自ら計画を立て、実行し、評価し、目標が達成されるまで自身のアプローチを修正することが可能になりました。人間の役割は「ドライバー」から「レビュアー」へと移行し、それによりリサーチ業務の経済性そのものが根本から変わります。
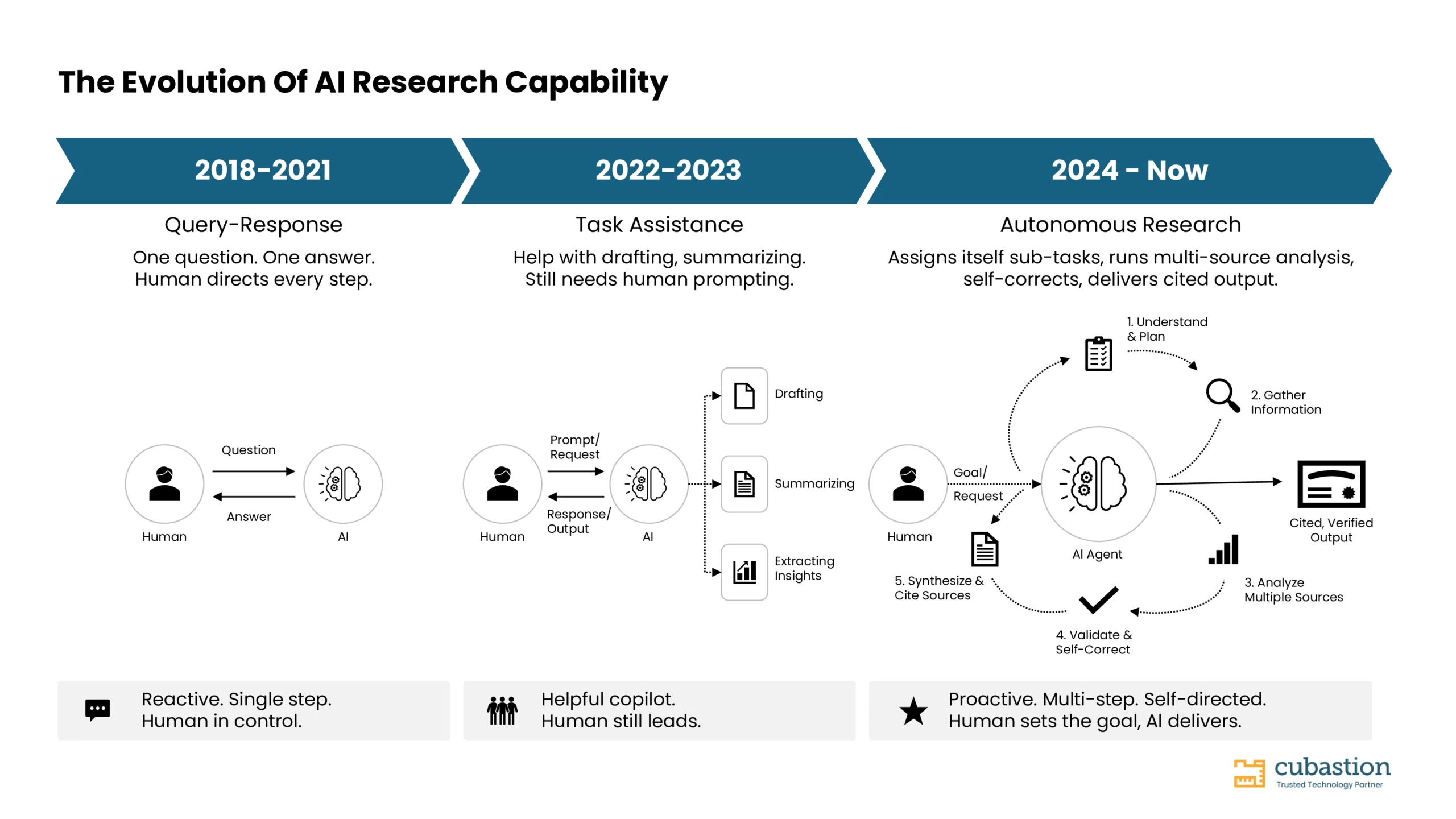
この飛躍を可能にしている技術的基盤が「Reactループ」です。これは「推論(Reasoning)」「実行(Acting)」「観察(Observing)」を繰り返す反復サイクルであり、厳密なリサーチャーの思考プロセスを模倣しています。エージェントは、必要な情報を判断し、それを取得し、内容を評価し、計画を更新し、目標が満たされるまで何十回もこのサイクルを継続します。
機械の内部:ディープエージェントが実際にどう思考するか
ディープエージェントのアウトプットを信頼し、そのプロセスを適切にガバナンスするためには、エージェントが「何を生成するか」ではなく「何を行うか」を理解することが不可欠です。実行時、ディープエージェントは継続的な意思決定ループとして動作します。目標を受領し、必要事項を判断し、情報を取得し、評価し、計画を更新する。これを何十回、何百回と回答が完成するまで繰り返すのです。
このプロセスを企業利用に耐え得る信頼性に高めているのが、以下の4つの構造的コンポーネントです。
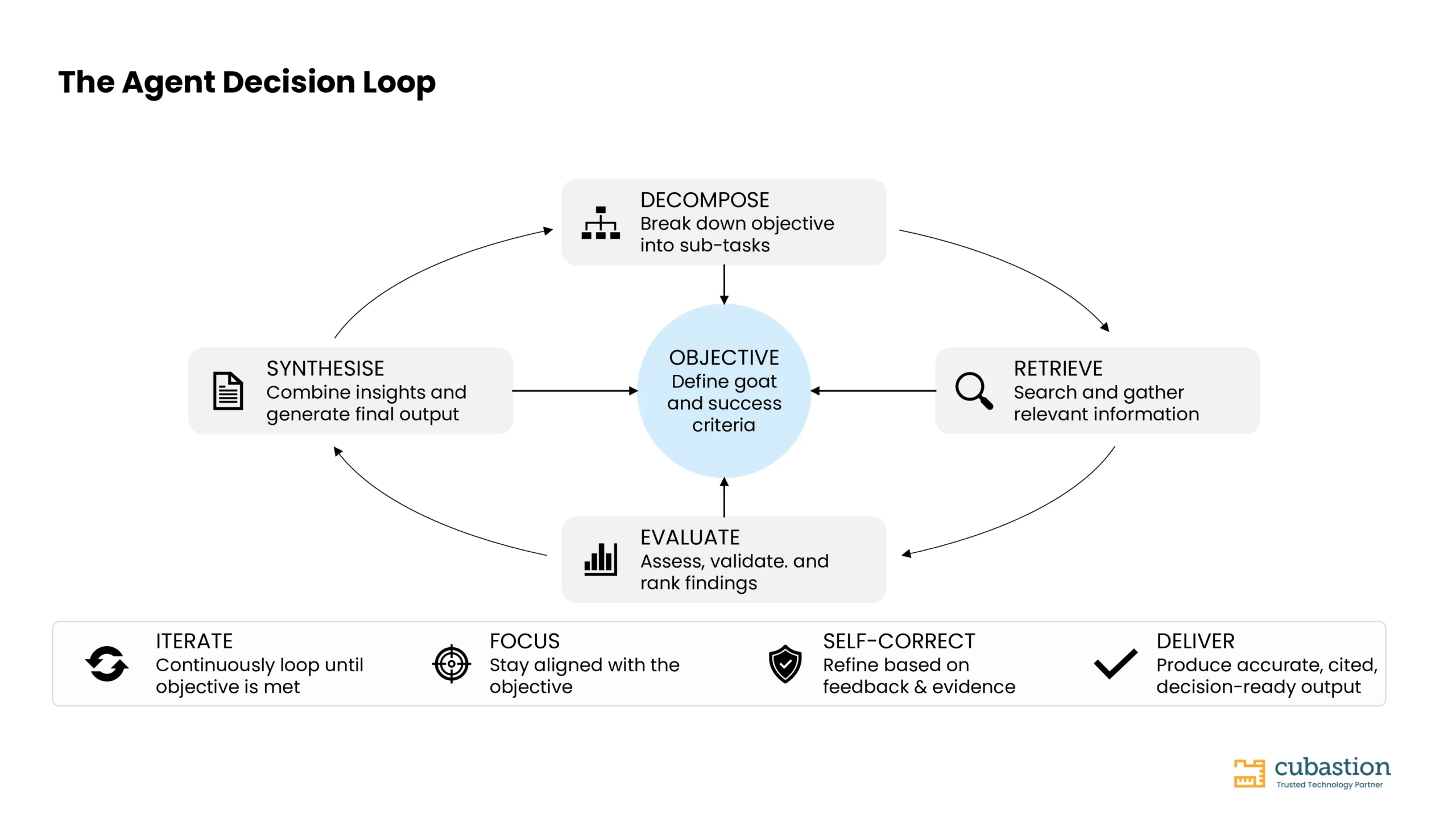
- タスクの分解 (Task Decomposition)行動に先立ち、エージェントは問題全体を俯瞰し、複雑な目標を追跡可能なサブタスクに分解します。これにより、長期にわたるマルチステップのセッションにおいても、エージェントが軌道を外れることを防ぎます。
- 並列サブエージェント実行 (Parallel Sub-Agent Execution)大規模なタスクでは、専門特化したサブエージェントが並行して稼働します。あるエージェントは学術文献を調査し、別のエージェントは財務データを分析し、さらに別のエージェントは規制情報をクロスチェックし、それらの結果を統括レイヤーに集約します。
- 永続的ワーキングメモリ (Persistent Working Memory)都度リセットされるチャットセッションとは異なり、ディープエージェントは中間的な知見をセッション全体を通じて参照可能な構造化ワークスペースに書き出します。これにより、初期の発見が後段の結論に反映されます。
- 自己批評と修正 (Self-Critique and Revision)結論を起案した後、エージェントは自身の論理を監査します。すべての主張に出典があるか、矛盾は解消されているか、当初の問いが完全に回答されているかを検証します。不足が残っていれば、作業を継続します。
ディープエージェント型リサーチが既に稼働している6つの産業
ディープエージェント型AIは、均一に適用される汎用的な生産性ツールではありません。最も価値の高い導入事例は、極めて垂直特化型であり、リサーチ量、統合の複雑性、アウトプットの重要性のいずれもが高い、特定産業の特定ワークフロー向けに構築されています。自動車産業においても、コネクテッドカー戦略、規制動向、サプライチェーンインテリジェンスなどの領域で導入が進んでいます。

とはいえ、成果が最も顕著に現れる領域を把握しているだけでは不十分です。技術を正しく導入する方法を知る必要があり、ここで多くの企業が指南を必要とします。
効果的なディープエージェント導入を支える5つの運用原則
ディープエージェントの導入に成功した企業は、いずれも同じ観察に到達しています。すなわち「技術そのものは困難な部分ではない」ということです。困難な部分は、アウトプットが信頼できるものとなり、ワークフローが持続可能となり、システムを利用する人間が「自身の判断が依然として必要とされる箇所」を正確に理解するように、導入を設計することにあります。
ディープエージェント導入を「ITプロジェクト」(インストール、設定、ローンチ)として扱う企業は、これを「ナレッジワークの構造的変革」として扱う企業に対し、確実に劣後します。両者を分かつ5つの原則を以下に示します。
- まずは特定の高付加価値リサーチタスクに錨を下ろす汎用エージェントは汎用的なアウトプットしか生み出しません。リサーチ負荷が最も高く、迅速かつ正確な回答の価値が最も具体的な領域から開始し、そこから展開していくべきです。
- 検証可能性を交渉の対象外とするすべてのエージェントの結論は、参照可能な出典に遡れなければなりません。自信を持って引用しつつも誤った情報を提示するエージェントは、エージェントが存在しないよりも悪い結果をもたらします。
- 人間の役割を、ローンチ後ではなく、ローンチ前に再定義する「リサーチを行うアナリスト」から「レビューし意思決定を行うアナリスト」への役割転換には、明示的な期待値設定が不可欠です。この変革を事前に設計したチームはそれを受容し、導入の途中で気づいたチームは抵抗します。
- ドメイン特化型の学習とデータ接続に投資する汎用導入とドメインチューニングされた導入の品質格差は大きく、時間の経過とともに拡大します。
- 初日からフィードバックループを組み込むエージェントのアウトプットは評価可能であるべきであり、エラーは上流に伝播されるべきです。構造化された改善サイクルがなければ、品質は積み上がるのではなく、漂流します。
これらの原則は、自動的に実現するものではありません。導入の初期段階におけるアーキテクチャ上の意思決定が必要です。これこそが、Cubastionのビジネスソリューションが提供するために構築されてきた価値です。
Cubastionとのパートナーシップが、AI駆動型リサーチ変革を確実にする理由
ディープエージェント型AIの導入に成功している企業の多くは、ある一つの特徴を共有しています。それは「単独で取り組まなかった」ということです。Cubastionは、誤答が現実的なコストを伴うエンゲージメントにおいて、検索アーキテクチャ、ドメイン・ファインチューニング、ガバナンス、チェンジマネジメントに至るフルスタックを実践してきました。
ある中堅金融サービス事業者向けには、40以上のマーケットにわたりOpenAI Deep Researchを導入し、独自データフィードおよび社内SharePointリポジトリと統合しました。週に60アナリスト時間を要していたプロセスは、毎週月曜朝に完全自律で稼働するブリーフィングパイプラインへと転換し、すべてのレポートに出典が付され、レビュー済みの状態で配信されるようになりました。
すべてのエンゲージメントで一貫した5つの提供価値

クライアントが一貫して実感する成果は、リサーチサイクルが「日単位」から「時間単位」へと短縮されること、アナリストが「情報検索」から「戦略立案」へとシフトすること、そして組織知が「断片化された状態」から「確実にアクセス可能な状態」へと転換することです。
依然として可変要素として残るのは、技術ではありません。それを吸収する組織の準備度です。すなわち、適切なワークフローの特定、適切なデータの接続、適切なガバナンスの整備、そしてリサーチとの根本的に異なる関係性に向けた人材の準備です。
Cubastionは、企業がこのギャップを埋めることを支援します。初めてのディープエージェント・パイロット導入を検討されている段階であれ、既存導入のスケール拡大を進めている段階であれ、私たちは方法論、ドメイン経験、技術アーキテクチャを提供し、貴社の投資が、可視で、説明可能で、持続的な成果を生み出すことを確実にします。
